
1957년에 Frank Rosenblatt가 Mark I Perceptron Machine을 개발했다.
최초의 perceptron을 구현한 기계이다.
perceptron은 wx+b와 유사한 함수를 사용한다.
왜 똑같은게 아니고 유사하냐면 출력값이 1 또는 0이기 때문이다.
가중치 w는 update rule이 존재한다.
하지만 이것은 w를 조절하면서 맞추는 식이였다.

1960년대에는 Widrow와 Hoff가 Adaline과 Madaline을 개발했다.
이것은 최초의 multilayer perceptron network를 구현한 기계였다.
하지만 backpropagation과 같은 알고리즘은 없었다.

최초의 backpropagation은 1986년에 Rumelhart가 제안했다.
chain rule과 update rule을 확인할 수 있다.
이때가 최초로 network를 학습시키는 개념이 정립되기 시작했다.

2006년에 RBM을 통해 DNN의 학습 가능성을 보여줬다.
하지만 이때까지도 모던한 NN은 아니였다.
backpropagation을 수행하려면 세심한 초기화가 필요했다.
초기화를 위해 전처리 과정이 필요했고
각 히든레이어 가중치를 학습해야했다.
이렇게 초기화된 히든 레이어를 이용해서
전체 신경망을 backpropagation 하거나 fine tune을 수행했다.

실제로 NN이 유명세를 타기 시작한 때는 2012년부터이다.
NN이 음성 인식에서 아주 좋은 성능을 나타냈기 때문이다.
또한 2012년에 영상 인식 관련해서도 유명한 AlexNet이 나온다.
이 논문은 ImageNet classification에서 최초로 NN을 사용했고 결과는 굉장했다.
AlextNet은 ImageNet benchmark의 error를 그때 당시 극적으로 감소시켰다.
이후 ConvNet은 널리 쓰이고 있다.

다시 1950년대로 돌아가 Hubel & Wiesel이 일차 시각피질의 뉴런에 관한 연구를 수행한 것을 떠올려보자.
고양이 뇌에 전극을 꼽아서 다양한 자극을 주고 실험을 진행했다.
여기서 뉴런이 oriented edge와 shape와 같은 것들에게 반응한다는 것을 알게 되었다.

고양이 실험에서 내린 중요한 결론 중 하나는
피질(cortex) 내부에 topograhical mapping이 존재한다는 것이다.
피질 내 서로 인접해 있는 세포들은 visual field에서 지역성을 나타낸다.
위의 오른쪽 그림을 보면 해당되는 spatial mapping을 볼 수 있다.
쉽게 말하면 눈으로 본거를 피질에서 공간적으로 표현된다고 볼 수 있다.
또 다른 중요한 점은 뉴런들이 계층 구조를 지니고 있다는 점이다.

다양한 종류의 시각 자극에 대해 시각 신호가 가장 먼저 도달하는 위치가
망막으로부터 시각적인 정보를 뇌로 전달하는 망막절 세포(retinal ganglion cell)이라는 것을 발견했다.
가장 상위에는 simple cell들이 있는데
다양한 edge의 방향과 빛의 방향에 대해 반응을 나타냈다.
그리고 simple cell이 complex cell과 연결되어 있다는 것을 발견했다.
complex cell은 빛의 방향 뿐만 아니라 움직임에 대해서도 반응을 나타냈다.
복잡도가 증가한 hypercomplex cell들은
끝 점(end point)에 반응하는 것을 나타냈다.
이러한 발견들로부터 corner나 blob에 대한 아이디어를 얻기 시작했다.

1980년에 Neocognitron은 Hubel & Wiesel의
simple/complex cell 아이디어를 사용한 최초의 NN이다.
simple/complex cell을 교차시켰다.
simple cell은 학습 가능한 파라미터를 가지고 있었고,
complex cell은 pooling과 같은 역할로 구현했으며 작은 변화에 simple cell보다 좀 더 강인하다.
지금가지 1980년대까지의 업적을 살펴보았다.

1998년 Yann LeCun이 최초로 NN을 학습시키기 위해 backpropagation과
gradient-based learning을 적용했다.
이 방법은 우체국에서 문자 인식과 숫자 인식에 쓰였으며 잘 동작했다.
하지만 네트워크를 더 크게 만들지 못했고 숫자 데이터는 단순했다.

2012년 AlexNet이 CNN의 현대화를 불러 이르켰다.
이는 Yann LeCun의 CNN과 크기 다르지 않고 단지 더 크고 깊어졌다.
또한 ImageNet과 같은 대량의 dataset을 활용할 수 있었으며 GPU를 활용할 수 있었다.

오늘날 ConvNets 어디에서나 쓰인다.
AlexNet의 ImageNet classification 결과를 보면 이미지 검색(retrieval)에 좋은 성능을 보인다.
위의 그림에서 오른쪽 그림을 보면 유사한 특징을 매칭시키는데 탁월하다는 것을 알 수 있다.

Detection에서도 ConvNet을 사용한다.
이미지에서 객체를 찾고 bounding box를 그린다.
segmentation도 수행할 수 있다. 이는 bbox만 치는게 아니라
객체를 구별하는데 픽셀 하나하나를 classification한다.

ConvNets은 자율주행 자동차에도 활용될 수 있다.
대부분 작업을 GPU가 수행하며, 병렬처리를 통해 ConvNet을 효과적으로 학습하고 추론할 수 있다.
임베디드 시스템에서도 동작하며, 최신 GPU에서도 가능하다.

위 그림은 ConvNet을 활용한 다양한 어플리케이션의 예를 보여준다.
ConvNet을 단일 이미지와 시간적 정보를 이용하여 비디오에도 활용할 수 있다.

pose estimation도 가능하다.
어깨나 팔꿈치와 같은 다양한 관절 포인트를 인식할 수 있다.
사람의 비정형적인 포즈를 잘 검출하는 것을 볼 수 있다.
강화학습을 통해 게임을 하거나 바둑을 두는것도 가능하다.
이러한 여러 작업들에서 ConvNet은 아주 중요한 역할을 한다.

또 다른 예로는 의료 영상을 가지고 해석하거나 진단을 하는데 활용되는 것이다.
우주 은하를 분류하거나 표지판을 인식할수도 있다.

Kaggle Chanllange에서 고래를 분류하는 작업도 있었다.
항공 지도를 활용하여 길과 건물 인식을 수행할 수 있다.

classification과 detection에서 좀 더 나아가 image captioning을 수행할 수 있다.
image captioning은 해당 이미지의 설명을 문장으로 생성한다.

또한 Neural Network를 이용해서 멋진 예술작품도 만들어 낼 수 있다.
위의 그림 왼쪽은 Deep Dream 알고리즘의 결과를 나타낸다.
오른쪽 그림은 style transfer라는 방법은 원본 이미지를 가지고 특정 화풍으로 다시 그려주는 알고리즘이다.
오른쪽 하단 그림은 원본 주택 이미지를 반 고흐의 별이 빛나는 밤의 화풍으로 바꾼것이다.
CNN에 대해 어떻게 동작하는지 알아보자.
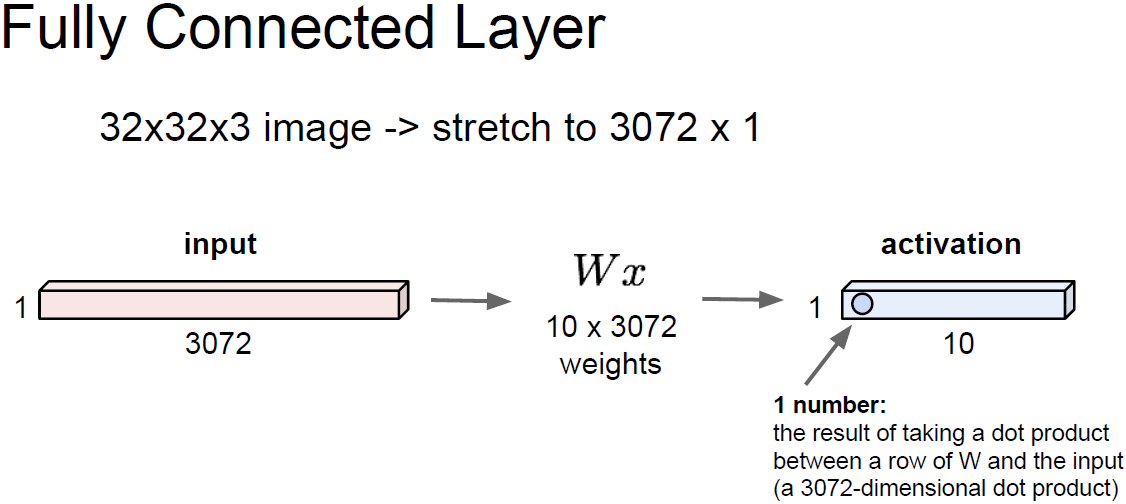
우선 FC를 살펴보자.
위의 그림에서 32x32x3의 이미지를 입력으로 활용했다.
이 이미지를 길게 펴서 3072-dim의 벡터로 만들었다.
그리고 10x3072 크기의 가중치 W와 곱하면(Wx) activation을 얻을 수 있다.
activation은 10개의 행으로 되어 있으며 3072-dim 입력과 가중치 W를 내적한 결과를 나타낸다.
그러면 어떤 하나의 숫자를 얻을 수 있는데 이는 neuron 중 하나의 값이라고 할 수 있다.
위 예시는 10개의 출력이 있는 경우이다.

conv layer와 FC layer의 주요 차이점은
conv layer는 기존의 spatial 구조를 보존한다는 것이다.
기존의 FC layer가 입력 이미지를 길게 폈다면
conv layer는 이미지 구조를 그대로 유지한다.

위의 그림에서 파란색 작은 필터가 가중치 W가 된다.
5x5x3 필터가 이미지를 슬라이딩하면서 공간적으로 내적(dot product)을 수행한다.
필터는 항상 입력의 깊이(depth)만큼 확장된다. (입력 깊이 3, 필터 깊이 3)
위의 예제는 32x32 이미지에 필터 크기가 5x5이지만
depth를 보면 입력의 전체 depth를 취한다. 여기서는 5x5x3이 된다.

이 필터 w를 가지고 전체 이미지에 내적을 수행한다.
필터 w와 이에 해당하는 이미지의 픽셀을 곱한다.
필터의 크기가 5x5x3이 의미하는 것은 그 만큼 곱셈연산을 수행한다는 의미이다. (5x5x3 = 75)
추가로 bias term이 하나 있을 수 있다.
w에 transpose를 한 이유는 행벡터(1x75)를 만들어 내적을 하기 위한 것이다.
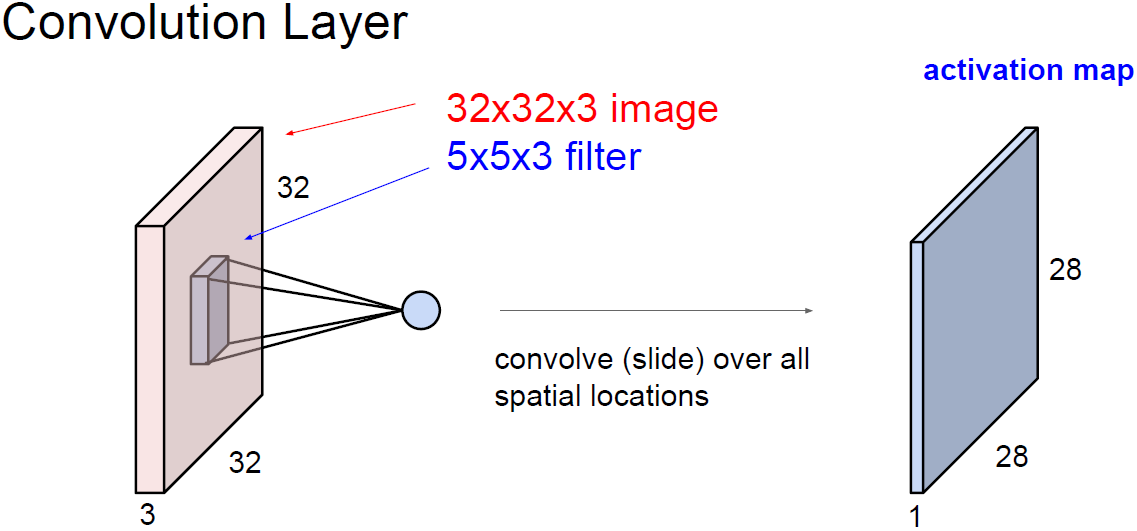
convolution은 이미지의 좌측 상단부터 필터가 슬라이딩하면서 수행된다.
필터의 모든 요소를 가지고 내적을 수행하게 되면 하나의 값을 얻을 수 있다.
그리고 슬라이딩을 해서 반복한다.
이렇게 나온 값들을 output activation map의 해당 위치에 저장한다.
위의 그림에서 입력 이미지와 출력 activation map의 차원(dim)이 다른것을 볼 수 있다.
입력은 32x32이고 출력은 28x28이다.
출력 크기는 슬라이딩을 어떻게 하느냐에 따라 달라질 수 있지만 보통 1씩 건너서 슬라이딩한다.

또 다른 하나의 필터를 이용하여 전체 이미지에 convolution 연산을 수행한다.
또 다른 같은 크기의 activation map을 얻게된다.
보통 이처럼 여러개의 필터를 이용한다.
왜냐하면 필터마다 다른 특징을 추출하기 위함이다.
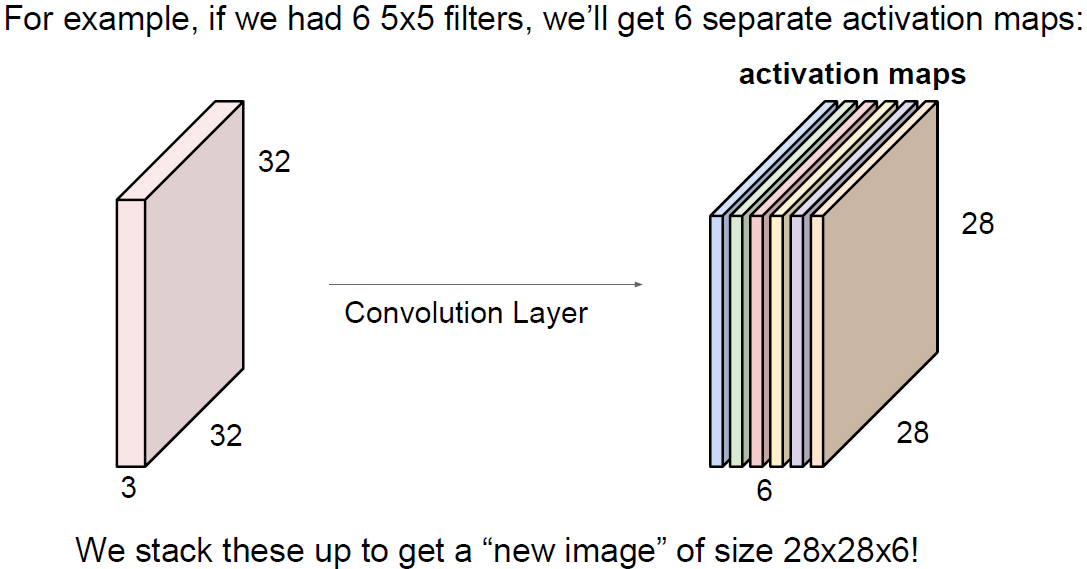
하나의 Layer에서 원하는 만큼의 필터를 사용할 수 있다.
위 그림에서는 5x5x3크기의 필터 6개를 사용했다

CNN은 보통 conv layer의 연속된 형태를 이룬다.
각각 conv layer를 쌓아 올리면 linear layer로 된 NN이 된다.
그 사이에 ReLU같은 activation function을 추가하여 비선형성을 만든다.
이렇게 되면 conv-relu가 반복되고 중간중간에 pooling layer도 들어간다.
그리고 각 layer 출력은 다음 layer의 입력이 된다.
각 layer는 여러개의 필터를 가지고 있고 각 필터마다 각각의 activation map을 만든다.
이런식으로 여러개의 layer를 쌓으면 각 필터들을 계층적으로 학습할 수 있다.
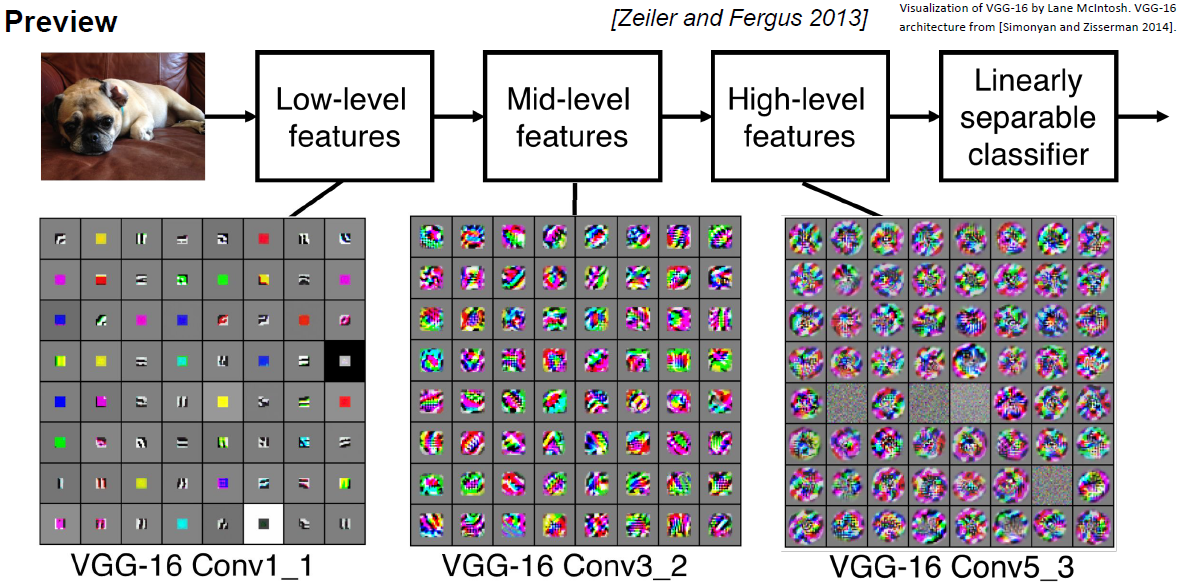
앞쪽에 있는 필터들은 edge와 같은 low level feature를 학습한다.
mid level feature를 보면 corner나 blob과 같은 좀 더 복잡한 특징을 가지게 된다.
high level feature를 보면 객체와 비슷한 것들을 특징으로 가지는 것을 볼 수 있다.
이는 layer의 계층에 따라 단순하거나 복잡한 특징을 뽑는다는것을 보여준다.

이러한 현상은 Hubel & Wiesel의 이론과도 잘 맞는다.
네트워크 앞단에는 단순한 작업을 처리하고 뒤로 갈수록 점점 더 복잡해지는것이다.
이러한 현상은 강제로 학습시킨것이 아니라
계층적 구조를 설계하고 역전파로 학습을 시켜서 나온 결과이다.
여러개의 각 필터는 이런식으로 학습이 된다.

위의 그림은 5x5 필터의 출력인 activation map의 visualization한것이다.
상단의 작은 그림은 5x5 필터가 어떻게 생겼는지 보여준다.
입력 이미지는 자동차의 헤드라이트 부분이다.
빨간 네모박스를 보면 edge를 찾고 있다.
이 필터를 슬라이딩 시키면 이 필터와 비슷한 값들은 값이 커지게 된다. (하단 빨간 네모박스)
이미지 중 어느 위치에서 각 필터가 크게 반응하는지 알 수 있다.

CNN은 입력 이미지를 여러 layer에 통과시킨다.
첫 번째 conv layer후에 ReLU non-linear layer를 통과한다.
conv-relu-conv-relu를 수행한 뒤 pooling layer를 통과한다.
pooling은 activation map 사이즈를 줄이는 역할을 한다.
CNN 끝단에는 FC layer가 있다.
conv layer 마지막 출력과 연결되어 최종 스코어를 계산한다.
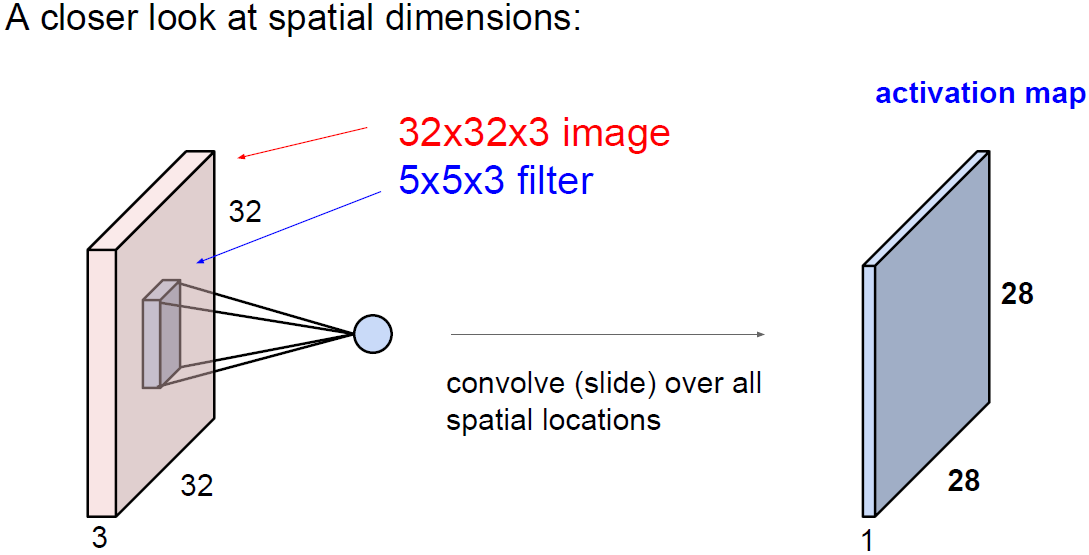
32x32x3 이미지가 있고 5x5x3 필터를 가지고 연산을 수행한다고 생각해보자.
왜 출력이 28x28이 나오게 될까?

간단한 예시로 7x7 입력에 3x3 필터가 있다고 가정해보자.
이미지 좌측상단부터 필터를 슬라이딩하면서 내적을 수행한다.
내적의 출력 값들은 activation map의 좌측 상단부터 저장된다.
다음 단계를 필터를 오른쪽으로 한칸 슬라이딩한다.
그럼 또 하나의 내적 값을 얻을 수 있다.
이런식으로 반복하다보면 결국 5x5의 activation map을 얻을 수 있다.
이 필터는 좌우 방향과 상하방향으로 5번씩만 슬라이딩할 수 있다.

슬라이딩을 두 칸씩 움직일수도 있다.
여기서 움직이는 칸을 stride라고 한다. stride를 2로 설정하면 슬라이딩을 2칸씩 건너뛰면서 하는 것이다.
그럼 결국 3x3 activation map을 얻게될것이다.

그렇다면 stride가 3일때 출력 사이즈는 몇이 될까?
이때는 필터가 이미지를 슬라이딩해도 모든 이미지를 커버할 수 없게된다.
이렇게되면 데이터 손실도 있고 불균형한 결과를 볼 수 있다.

위의 그림은 상황에 따라 출력 사이즈가 어떻게 되는지 계산할 수 있는 수식을 나타낸다.
입력의 차원이 N이고 필터 사이즈가 F이고 stride가 주어지면 출력 크기는 (N-F) / stride + 1이 된다.
이를 이용해서 어떤 필터 크기를 사용해야 하는지 알 수 있다.
또한 어떤 stride를 사용했을때 이미지에 맞는지, 몇 개의 출력값을 낼 수 있는지도 알 수 있다.

출력 사이즈를 입력 사이즈와 동일하게 만들기 위한 방법 중
흔히 쓰이는 방법이 zero padding이다.
이미지의 경계를 포함할 수 있는 방법이기도 하다.
zero pad는 이미지의 가장자리에 0을 채워 넣는다.
이렇게되면 왼쪽 상단 끝부터 conv 필터 연산을 수행할 수 있다.
7x7입력에 3x3필터 연산시 zero padding을 넣는다면 출력은 7x7이 된다.
일반적으로 필터 크기가 3일때 zero pad는 1로,
5일때 2로, 7일때 3을 사용한다.
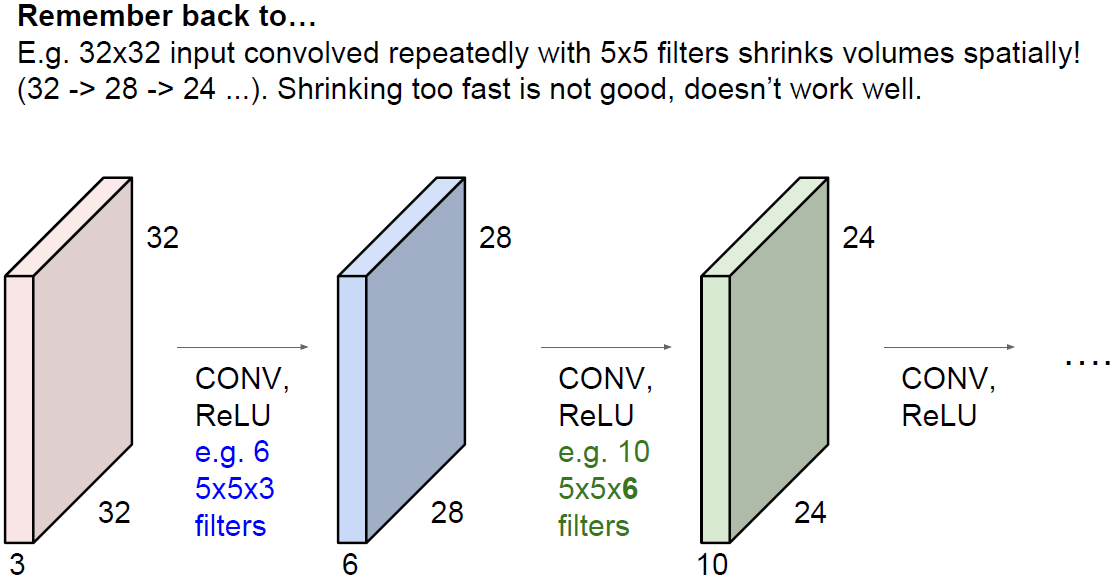
여러 layer를 계층적으로 쌓을때 zero padding을 하지 않는 다면
출력 사이즈가 계속 줄어들것이다.
깊은 네트워크가 있다면 activation map은 계속 줄어들고 엄청 작아진다.
그렇게되면 일부 정보를 잃게 될것이고 원본 이미지를 표현하기에는 너무 작은 값을 사용하게 된다.
출력 크기가 줄어드는 이유는 입력의 가장자리를 계산하지 못하기 때문이다.

입력 이미지 크기가 32x32x3이고 5x5x3 필터 10개 있다.
여기서 stride를 1로 하고 padding을 2로 했을때 출력사이즈는 몇이 될까?
입력 사이즈 F가 32가 되고 padding으로 2씩 증가시키면 32+4 = 36이된다.
여기서 필터 사이즈 5를 빼고 stride 1로 나누고 1을 더하면 각 필터는 32x32가 된다.
전체 필터 개수는 10개로 10개의 activation map이 만들어진다.
그럼 전체 출력 크기는 32x32x10이 된다.

그럼 파라미터는 총 몇개일까?
하나의 필터는 5x5x3개의 파라미터가 있고 하나의 bias를 가질 수 있다. 75 + 1 = 76
이러한 필터가 10개기 때문에 총 파라미터의 개수는 76 * 10 = 760개이다.

위의 그림은 conv layer의 요약이다.
일반적인 필터 사이즈로 3x3, 5x5를 사용한다.
stride는 1이나 2를 많이 쓴다.
padding은 설정에 따라 조금씩 다르다.
보통 필터 개수는 32, 64, 128, 512처럼 2의 제곱수로 설정한다.

1x1 convolution은 depth를 조절할때 활용된다.
1x1은 3x3이나 5x5 등 처럼 공간적인 정보를 이용하지는 않는다.
하지만 depth 만큼은 연산을 수행한다.
그렇기 때문에 1x1 conv는 입력 전체의 depth에 대한 내적을 수행하는것과 같다.
위의 그림은 입력이 56x56x64이다. 여기서 32개의 1x1x64 convolution을 수행하면
56x56x32 크기의 activation map이 생성된다.

conv layer를 뇌의 neuron관점에 생각해보자.
오른쪽 그림은 내적과 같은 아이디어를 나타낸다.
입력 x가 들어오면 가중치 w와 곱한다. w는 필터값이라고 할 수 있다.
이는 하나의 값을 출력한다.
그렇지만 가장 큰 차이점은 neuron이 local connectivity를 가지고 있다는 점이다.
conv layer 처럼 슬라이딩을 하는것이 아니라 특정 부분에만 연결되어 있다.
하나의 neuron이 한 부분만 처리하고, 이러한 neuron들이 모여서 전체 이미지를 처리한다.
이런식을 spatial 구조를 유지한채로 layer의 출력인 activation map을 만든다.

5x5 필터는 각 neuron의 receptive field가 5x5라고 할 수 있다.
receptive field는 하나의 neuron이 한 번에 수용할 수 있는 영역을 의미한다.
여기서 필터가 5개라고 가정한다. (5x5x5)

출력값은 위 그림에서 파란색 volume처럼 생긴다.
출력의 크기는 28x28x5인 3D grid가 된다.
여기서 어떤 한 점을 찍어서 depth 방향으로 바라보면
이 5개의 점은 정확하게 같은 지역에서 추출된 서로 다른 특징이라고 볼 수 있다.
각 필터는 서로 다른 특징을 추출한다.
그렇기 때문에 각 필터는 이미지에서 같은 지역을 슬라이딩하더라도
서로 다른 특징을 뽑는다고 할 수 있다.

pooling layer는 representation을 더 작게 하고 더 관리하기 쉽게 해준다.
즉, 파라미터 수를 줄이는 것이다.
공간적 불변성(invariance)를 얻을 수 있다.
pooling layer의 역할은 심플하다. 바로 downsampling하는 것이다.
예를 들어 224x224x64의 입력이 있다면 pooling을 통해 112x112x64로 '공간적으로' 줄여준다.
depth에는 아무런 영향이 없다.
최대값을 뽑는 max pooling이 일반적으로 쓰인다.

pooling에도 필터의 크기를 정할 수 있다.
필터의 크기는 얼만큼의 영역을 한번에 묶을지 정하는것이다.
위의 그림에서 왼쪽은 4x4 입력이고 여기에 stride 2의 2x2 max pooling을 수행하면
오른쪽 그림과 같이 계산된다.
conv layer처럼 슬라이딩하면서 연산한다.
max pooling이기 때문에 conv처럼 내적이 아니라 필터 안에서 가장 큰 값 하나를 뽑는다.
왼쪽 빨간색 영역을 보면 6이 가장 크고 녹생 영역은 8이 가장 크다.
노란색 영역은 3, 파란색 영역은 4가 가장 크다.
pooling을 수행할때는 겹치지 않게 슬라이딩하는것이 일반적이다.
최근은 pooling보다 stride를 이용하여 downsampling을 수행한다.
좀 더 좋은 성능을 나타낸다고 한다.

pooling layer는 입력이 W(width), H(height), D(Depth)라고 할때
필터 size를 정해줄 수 있다.
여기에 stride까지 정해주면 앞에서 언급한
conv layer에서 사용했던 수식을 그대로 이용할 수 있다.
(W - Filter Size) / Stride + 1 이 된다.
pooling layer는 padding을 수행하지 않는다.
왜냐하면 pooling의 목적은 downsampling이고
conv layer처럼 가장자리 값을 계산 못하는 경우가 없기 때문이다.
일반적으로 pooling 필터 사이즈는 2x2, 3x3이며,
stride는 보통 2로 한다.

conv layer가 있고 비선형성인 activation function ReLU layer를 통과한다.
downsampling을 할 때는 pooling layer를 섞어준다.
마지막에는 FC layer가 있다.
FC의 입력으로 사용되는 마지막 conv layer의 출력은 3차원 volume으로 이루어진다.
이 값들을 전부 1차원 벡터로 만들어서 FC layer의 입력으로 사용한다.
이렇게되면 ConvNet의 모든 출력을 서로 연결하게 되는것이다.
마지막 FC layer부터는 공간적 구조(spatial structure)를 신경쓰지 않게된다.
전부 하나로 통합시켜서 최종적인 추론을 수행한다.
그렇게 되면 score가 출력으로 나오게 된다.
최근은 pooling이나 FC layer를 점점 없애는 추세이다.
conv layer만 깊게 쌓는 것이다.
'머신러닝 > CS231n (2017)' 카테고리의 다른 글
| Lecture 6: Training Neural Networks I (0) | 2020.10.05 |
|---|---|
| Lecture 4: Backpropagation and Neural Networks (0) | 2020.09.17 |
| Lecture 3: Loss Functions and Optimization (0) | 2020.09.14 |
| Lecture 2: Image Classification Pipeline (0) | 2020.09.12 |
| Lecture 1: Introduction (0) | 2020.09.07 |