part 1에서는 활성 함수, 데이터 전처리, 가중치 초기화, batch normalization, 학습 과정, 하이퍼파라미터 최적화를 다룬다.
먼저 activation functions을 살펴보자.

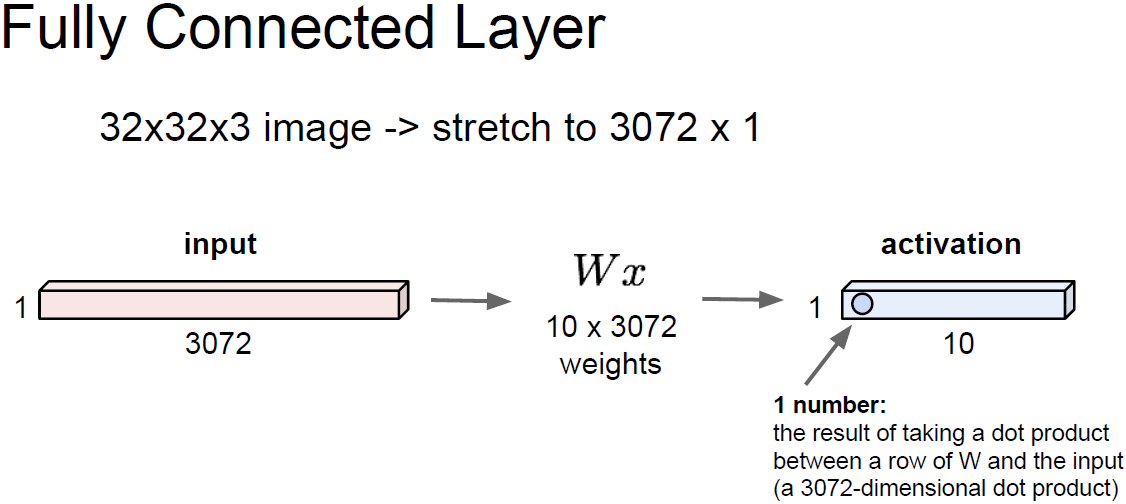
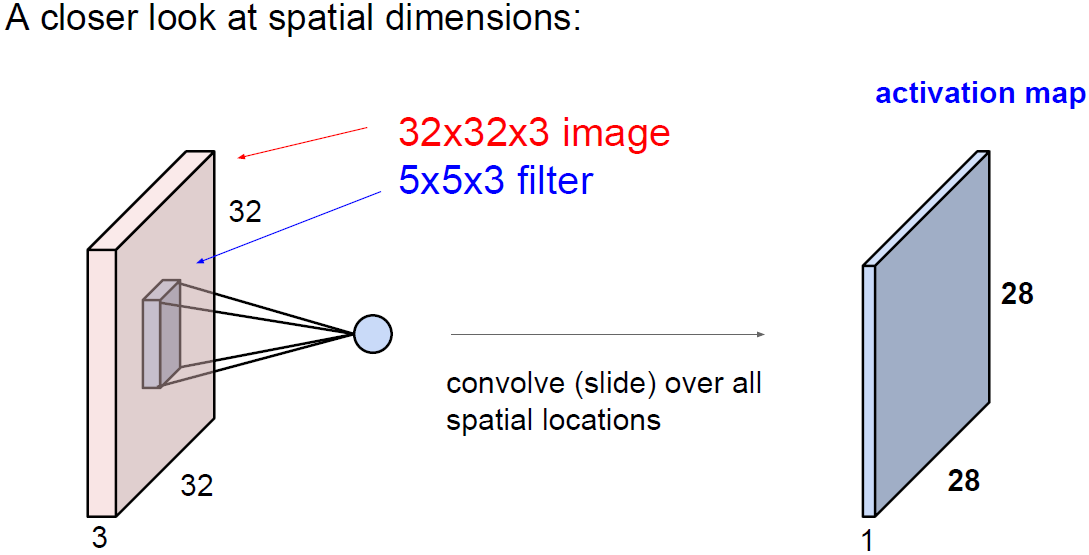
input으로 데이터 입력이 들어오고 가중치와 곱한다. (행렬 내적)
이는 FC 혹은 CNN이 될 수 있다.
이후 활성 함수(activation function), 즉 비선형 함수를 통과하게 된다.

위의 그림은 다양한 활성 함수들의 예시를 보여준다.
먼저 sigmoid를 살펴보자.

sigmoid는 입력을 받아서 0~1 사이의 값이 되도록 한다.
입력이 크면 1에 가깝고, 입력이 작으면 0에 가깝게 된다.
0 근처의 구간을 보면 선형 함수와 가까워 보인다.
이는 값이 적당할때 back-propagation이 잘될거라고 알 수 있다.
sigmoid는 역사적으로 유명하다.
왜냐하면 neuron을 firing rate를 saturation 시키는 것으로 해석할 수 있기 때문이다.
어떤 값이 0에서 1사이의 값을 가지고 있으면,
이를 firing rate로 생각할 수 있다.
생물학적으로는 0 보다 큰 값을 그대로 활성화 시키는 relu가 더 타당성이 크다는게 밝혀졌지만,
sigmoid 또한 firing rate를 saturation 시킨다는 관점에서 해석할 수 있다.
하지만 몇가지 문제점이 있다.
첫번째는 saturation 되는 것이 gradient를 없애는 것이다.
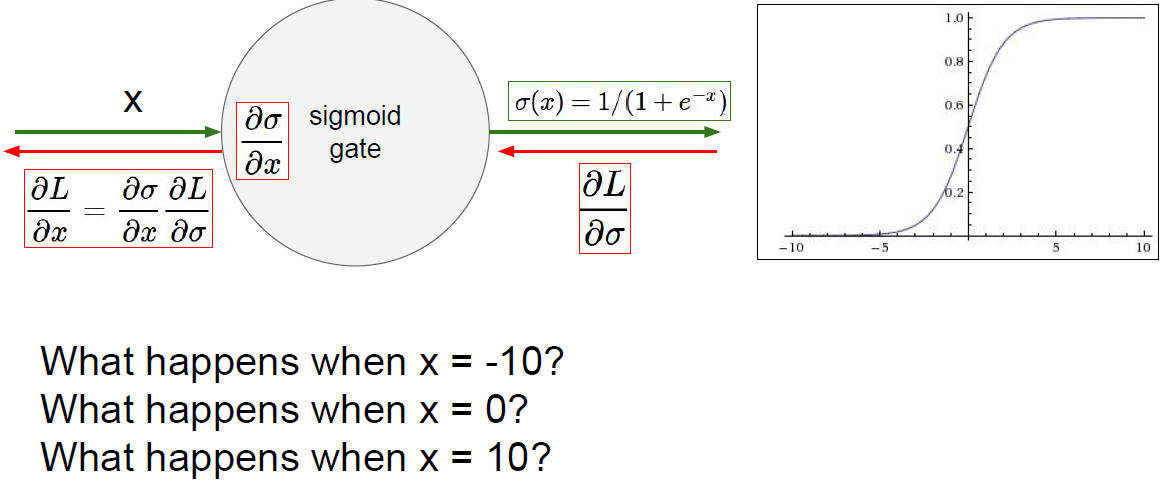
입력 x에 -10을 대입하고 sigmoid function을 통과하면 backprop에서 gradient는 어떻게 될까?
우선 dL / dSigma와 dSigma/dx의 곱이 sigmoid function의 gradient가 된다. (chain rule)
이렇게 계산된 gradient는 계속 아래로 흐르며 backprop 될 것이다.
그럼 입력 x가 -10일 때 gradient는?
0에 한없이 가깝게 된다.
sigmoid에서 음의 큰 값은 sigmoid가 평평하게 되고 gradient는 0에 가깝게 된다.
이렇게되면 0에 가까운 값이 계속 아래로 흐르며 backprop 될 것이다.
입력 x가 0이 면 어떻게 될까?
이 구간은 backprop가 잘 동작될 것이다.
그럴싸한 gradient를 얻을 수 있다는 말이다.
그럼 입력 x가 10이면 어떻게 될까?
x값이 양의 큰 값일 경우에도 sigmoid가 평평하게 되고 gradient가 0에 가깝게 된다.

두번째 문제는 sigmoid 출력이 zero centered 하지 않는 점이다.
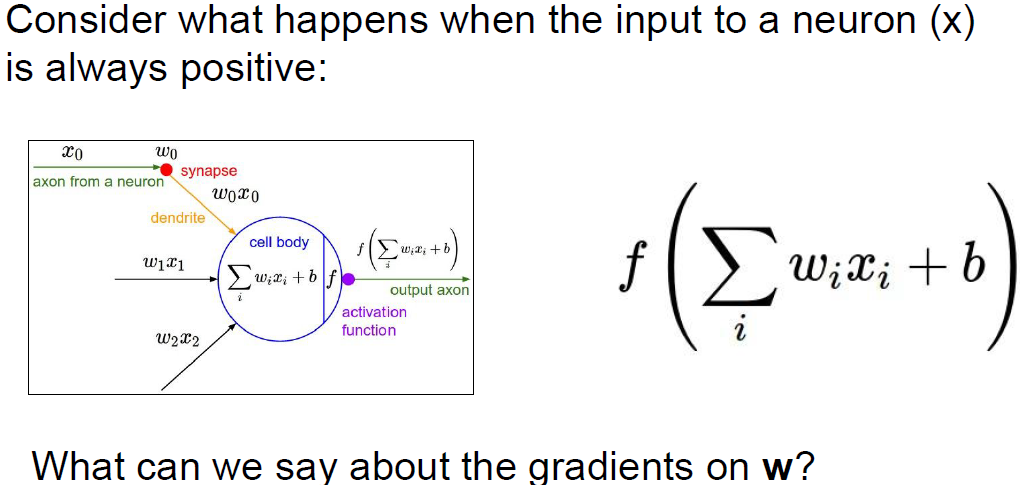
neuron의 입력이 항상 양수일때 어떻게 될까?
입력 양수 x는 가중치와 곱해지고 활성함수를 통과할 것이다.
이때 가중치 w에 대한 gradient를 생각해보자.
우선 dL/df(activation function)를 계산해서 loss가 아래로 흐를 것이다.
그리고 아래에서 (기본적으로 x라고 하자) local gradient가 있을텐데,
모든 x가 양수라면 해당 gradient는 '전부 양수' 혹은 '전부 음수'가 된다.

위에서 흘러온 dL/df(activation function)의 값이 양수 또는 음수가 될 것이다.
어떤 임의의 gradient가 흘러왔다고 가정하면,
우선 local gradient는 흘러온 값과 곱해질 것이고
df(activation function)/dw는 단지 x가 된다.
그렇게되면 gradient의 부호는 위에서 흘러온 gradient의 부호와 같아지게 된다.
이는 가중치 w가 모두 같은 방향으로만 움직일것이라는 것을 의미한다.
파라미터가 업데이트될 때 전부 증가하거나 전부 감소하게 된다.
이러한 gradient update는 굉장히 비효율적이다.
위의 그림 오른쪽은 w의 이차원 예제이다.
w에 대한 두개의 축이 있다.
전부 양수 혹은 음수로 update된다면 gradient가 이동할 수 있는 방향은
4분면 중 2개의 영역뿐이 되질 않는다.
2분면과 3분면의 방향으로만 업데이트 된다.
위의 오른쪽 그림에서 가장 최적의 w 업데이트가 파란색 화살표라고 가정하면,
초기 시작점(첫 빨간색 화살표)부터 업데이트한다고 했을 때,
파란색 방향으로 잘 내려갈 수 없게 된다.
때문에 여러번의 업데이트를 수행하게 된다. (빨간 화살표)
이것이 zero-mean data가 필요한 이유가 된다.
입력 x가 양수와 음수 모두 가지고 있다면,
전부 같은 방향으로 업데이트되는 일이 발생하지 않을 것이다.

세 번째 문제는 exponential 함수로 인해 계산 비용이 크다는 점이다.
하지만 이 문제는 그리 큰 문제가 아니다.
비용 측면에서 보면 내적과 같은 연산의 비용이 더 크다.
굳이 문제를 뽑자면 exp() 비용을 꼽는다는 것이다.

두 번째 활성 함수는 tanh이다.
sigmoid와 유사하지만 범위가 -1~1 사이의 값을 가진다.
가장 큰 차이점이라면 zero-centered라는 것이다.
이를 통해 sigmoid의 두 번째 문제가 해결된다.
하지만 saturation되기 때문에 여전히 낮거나 높은 값에서의 gradient가 0에 가깝게 되버린다.
tanh는 sigmoid보다는 조금 낫지만 그래도 위처럼 여전히 문제점이 있다.

이제 ReLU를 살펴보자.
이전에 봤던 CNN 모델들을 보면 conv layer 사이 사이에 ReLU가 있는 것을 볼 수 있었다.
ReLU 함수는 f(x) = max(0,x) 이다.
이 함수는 element-wise 연산을 수행하면서
입력이 0 미만의 음수면 출력이 0이 된다.
그리고 입력값이 양수면 출력은 입력값 그대로를 출력한다.
기존 sigmoid와 tanh에게 있었던 문제점들을 ReLU에서 살펴보면,
우선 양수 값에서는 saturation되지 않는 것을 알 수 있다.
이는 적어도 입력 공간의 절반은 saturation되지 않을 것이며 ReLU의 가장 큰 장점이다.
그리고 계산 효율이 뛰어나다.
sigmoid는 계산 수식에 지수 항이 있었다.
반면 ReLU는 단순 max 연산이기 때문에 계산이 상대적으로 빠르다.
ReLU를 사용하면 실제로 sigmoid와 tanh 보다 수렴속도가 거의 6배 정도로 빠르다.
그리고 위에 언급했지만 생물학적 관점에서도 ReLU가 sigmoid보다 좀 더 알맞다.
실제 신경과학적 실험을 통해 neuron을 관찰해보면
sigmoid 보다는 ReLU스럽다는 것이다.
2012년 ImageNet에서 우승한 AlexNet에서 처음 ReLU를 사용하기 시작했다.

하지만 zero-centered한 문제를 해결하지는 못했다.
또한 양수에서는 saturation되지 않지만 음수에서는 그렇지 못하다.

입력 x가 -10일 경우 어떻게 될까?
gradient는 0이 된다.
입력 x가 10일 경우는 linear한 영역에 속하기 때문에 그럴싸한 gradient가 계산될 것이다.
x가 0일때의 gradient는 0이 된다.
기본적으로 ReLU는 gradient의 절반을 죽이는 것이다.
그래서 dead ReLU라는 현상을 겪을 수 있다.

위의 그림은 training data를 2차원 초평면 공간에 나타낸 그림이다.
여기서 ReLU는 평면의 절반만 activatite 하는 것을 알 수 있다.
ReLU가 training data에서 떨어져 있는 경우 dead ReLU가 발생할 수 있다.
dead ReLU에서는 activate가 일어나지 않으며 업데이트 되지 않는다.
반면에 activate ReLU에서는 일부 activate되고 일부 activate하지 않을 것이다.
몇 가지 이유로 이런 일이 발생할 수 있다.
첫 번째는 초기화가 잘못됐을 경우이다.
가중치 평면아 training data에서 멀리 떨어져 있는 경우이다.
이런 경우 어떠한 입력에서도 활성화되지 않을 것이고 backprop이 일어나지 않을 것이다.
업데이트도 활성화도 되지 않는다.
또 하나의 경우는 learning rate가 지나치게 높은 경우이다.
처음에는 적절한 초기화 인해 적절한 ReLU로 시작할 수 있다고 해도
업데이트를 지나치게 크게 해서 가중치가 널뛴다면
ReLU는 데이터의 manifold를 벗어나게 된다. (ReLU가 데이터의 차원을 벗어났다고 생각하면 될듯)
위의 일들은 학습 과정에서 충분하게 일어날 수 있다.
그래서 처음에는 학습이 잘 되다가 갑자기 안되는 경우가 생기는 것이다.
그리고 실제로 학습이 된 네트워크를 살펴보면
10~20% 가량은 dead ReLU가 되어 있다.
ReLU를 사용하면 대부분의 네트워크가 이 문제를 겪을 수 있다.
하지만 이 정도는 네트워크 학습에 크게 지장이 없다고 한다.

그래서 실제로 ReLU를 초기화할 때 positive biases(0.01정도)를 추가해 주는 경우가 있다.
가중치 업데이트 시 activate ReLU가 될 가능성을 조금이라도 더 높혀주기 위함이다.
하지만 이 positive biases가 도움이 된다는 의견도 있고 그렇지 않다는 의견도 있다.
보통은 zero-bias로 초기화한다.

ReLU 이후에 살짝 수정된 Leaky ReLU가 나왔다.
ReLU와 유사하지만 negative 영역이 더 이상 0이 아니다.
negative에도 기울기를 살짝 주게되면 앞의 문제를 상당 부분 해결할 수 있다.
leaky ReLU의 경우 음수의 경우에도 saturation되지 않는다.
여전히 sigmoid와 tanh 보다 수렴을 빨리 할 수 있다.
또한 dead ReLU 현상도 사라진다.
또 다른 예시로 parametric rectifier, PReLU가 있다.
PReLU는 negative 영역에 기울기가 있다는 점에서 leaky ReLU와 유사하지만
기울기를 가중치 a(알파) 파라미터로 결정된다.
가중치 a는 정해진것이 아니며 backprop을 통해 학습이 된다.
activation function이 좀 더 유연해 질 수 있다.
ELU라는 것도 있다.

ELU는 ReLU의 이점을 그대로 가져온다.
하지만 ELU는 zero-mean에 가까운 출력값을 보인다.
zero-men에 가까운 출력은 leaky ReLU 및 PReLU가 가진 장점이였다.
하지만 leaky ReLU와 비교해보면 ELU는 negative영역에서 saturation된다.
ELU는 이런 saturation이 noise에 강인할 수 있다고 한다.
이런 deactivation이 좀 더 강인함을 줄 수 있다고 논문에서 주장한다.
ELU는 ReLU와 leaky ReLU의 중간정도라고 보면 된다.
ELU는 leaky ReLU처럼 zero-mean의 출력을 갖지만
saturation 관점에서 ReLU의 특성 또한 지니고 있다. (negative 영역)
Maxout이라는 활성화 함수도 있다.

무려 Generative Adversarial Network(GAN)의 창시자 이안굿펠로우가 2013년에 논문을 낸 내용이다.
dot product의 기본적인 form을 미리 정의하지 않는다.
대신 w1에 x를 내적한 값 + b1과 w2에 x를 내적한 값 + b2의 최대값을 사용한다.
maxout은 이 두 함수 중 최대값을 취한다.
maxout은 ReLU와 leaky ReLU의 좀 더 일반화된 형태이다.
왜냐하면 maxout은 위 두 개의 선형함수 중 최대값을 취하므로
선형이기 때문에 saturation되지 않으며 gradient를 잘 계산할 것이다.
하지만 문제점은 파라미터의 수가 두배가 된다는 점이다. (w1, w2)
가장 많이 쓰이는 활성 함수는 ReLU이다.
ReLU가 표준으로 많이 쓰이며 대부분 잘 동작한다.
하지만 위에도 언급했듯이 ReLU 사용 시 learning rate를 잘 설정해야 한다.
실제 네트워크를 학습하려면
일반적으로 입력 데이터에 대한 전처리가 필요하다.

가장 대표적인 전처리 과정은 zero-mean으로 만들고 normalize 해주는 것이다.
normalization은 보통 표준편차 이용해서 수행한다.
그럼 이러한 전처리가 왜 필요한것일까?
앞에서 입력이 전부 positive인 경우인 zero-centered에 대해 언급했다.

그렇게되면 모든 neuron이 positive gradient를 얻게 되고
이는 최적화가 아닌 최적화가 되버린다.
입력 데이터가 전무 positive 뿐만 아니라 전부 0 이거나 전부 negative인 경우에도 동일하다.
normalization을 해주는 이유는 모든 차원이 동일한 범위를 갖게 함으로써
전부 동등한 contribute를 할 수 있게 한다.

입력 데이터가 이미지일 경우 전처리로 zero-centering 정도만 해준다.
normalization은 하지 않는다.
왜냐하면 이미지는 이미 각 차원 간에 스케일이 어느정도 맞춰져있기 때문이다.
따라서 스케일이 다양한 여러 machine learning 문제와는 달리
이미지에서는 normalization을 엄청 잘 해줄 필요가 없다.
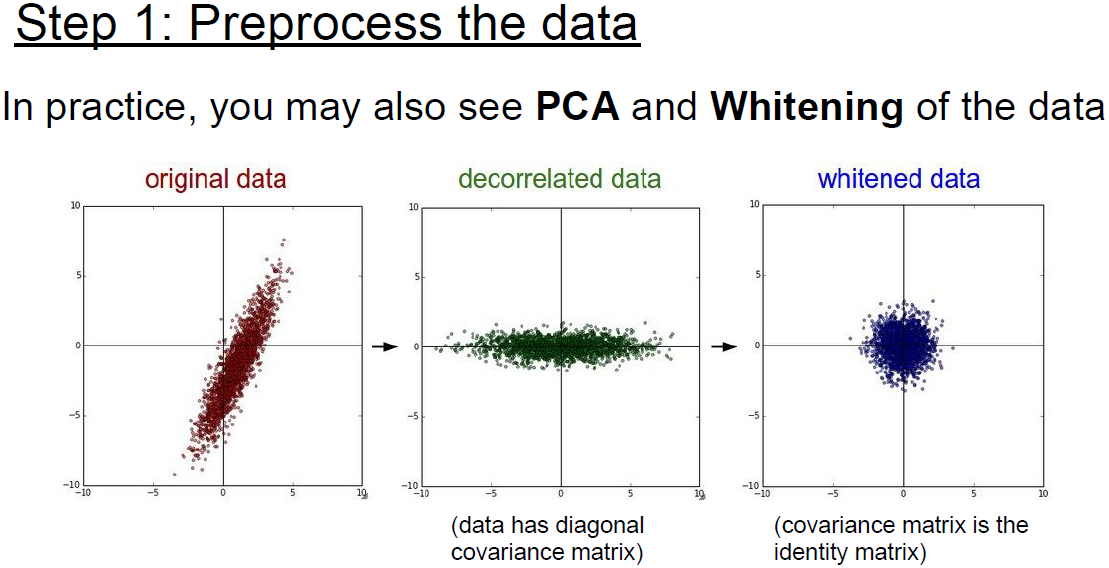
ml에서는 PCA 혹은 whitening과 같은 복잡한 전처리 과정도 있지만
이미지에서는 단순히 zero-mean 정도만 사용하고
normalization을 비롯한 여러 복잡한 방법들은 잘 쓰이지 않는다.
일반적으로 이미지를 다룰 때는 굳이 입력을 더 낮은 차원으로 projection 시키지 않는다.
CNN에서는 원본 이미지 자체의 spatial한 정보를 활용해서 이미지의 spatial 구조를 얻을 수 있도록 한다.

이미지에서의 zero-mean은
training data에서 평균 값을 계산하고 이 평균값을 네트워크에 입력되기 전에 빼준다.
inference할때도 training data 평균값을 빼주게 된다. (ex. AlexNet)
일부 네트워크는 이미지 컬러 채널 전체의 평균을 구하지 않고
채널마다 평균을 독립적으로 계산하는 경우도 있다. (ex. VGGNet)
이제 weight를 어떻게 초기화 시켜야 하는지에 대해 살펴보자.

위의 그림 two layer neural network를 예시로 보자.
우리가 할 일은 가중치 업데이트이다.
어떤 초기 가중치들이 있고 gradient를 계산해서 가중치를 업데이트할 것이다.
이때 모든 가중치를 0으로 하면 어떻게 될까?
그렇게된다면 모든 가중치가 동일한 연산을 수행하게 된다.
출력도 모두 같게 되며, 결국 gradient도 서로 동일하게 된다.
이는 모든 가중치가 똑같은 값으로 업데이트 된다.
모든 neuron이 동일하게 생기게 된다.
이는 모든 가중치를 동일하게 초기화시키면 발생하는 일이다.

이런 초기화 문제를 해결하는 첫번째 방법은
임의의 작은 값으로 초기화하는 것이다.
이 경우 초기 w를 standard gaussian(표준정규분포)에서 샘플링한다.
작은 네트워크라면 이런식의 초기화로 충분하지만
깊은 네트워크에서는 문제가 발생할 수 있다.
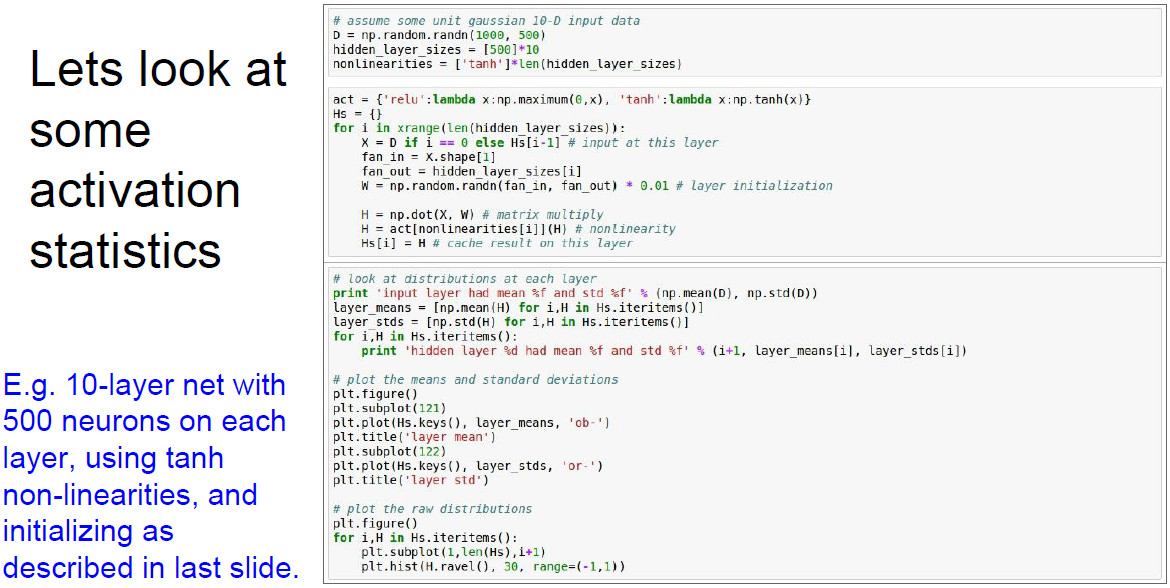
10개 layer로 이루어진 네트워크가 있다.
layer당 500개의 neuron이 있다.
활성 함수로는 tanh를 사용한다.
그리고 가중치는 임의의 작은 값으로 초기화시킨다.
데이터를 임의의 값으로 생성하고 forward pass를 시킨다.
그리고 각 레이어별 activation 수치를 통계화시키면 아래 그림과 같다.

위 수치는 각 layer 출력의 평균과 평균의 표준편차를 계산한 것이다.
중간의 왼쪽 그래프가 layer마다의 mean을 나타낸다.
평균은 항상 0 근처에 있다. (tanh 특성, zero-centered)
중간의 오른쪽 그래프가 layer마다의 std를 나타낸다.
이 std 보면 가파르게 줄어들면서 0에 수렴한다.
아래 그림은 layer별 std를 분포로 표현한 것이다.
첫번째 layer는 gaussian처럼 생긴 좋은 분포를 형성하고 있다.
문제는 w를 곱하면 곱할수록 값이 작아져서 출력 값이 급격히 줄어든다는 점이다.
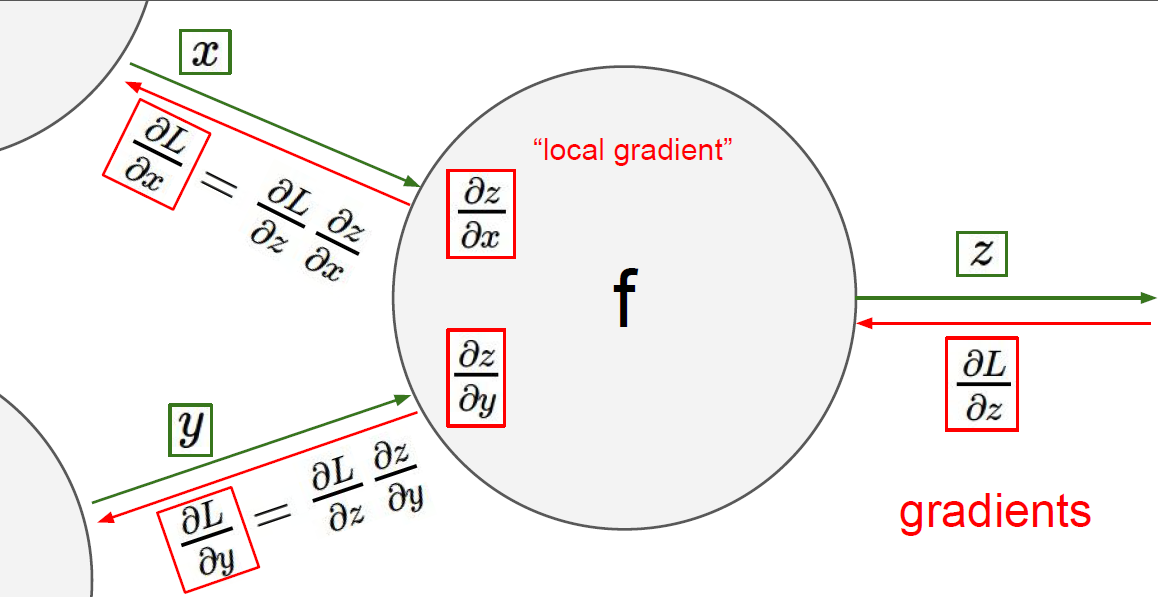
backwards pass로 다시한번 살펴보자.
각 layer의 입력이 매우 작은 값이다. 이 값들은 점점 0에 수렴한다.
backprop를 생각해보면 upstream gradient가 점점 전파된다.
현재 가중치를 업데이트하려면 upstream gradient에 local gradient를 곱해주면 된다. (chain rule)
우선 wx를 w에 대해 미분하면 local gadient는 입력 x가 된다. (w의 gradient는 x)
x가 매우 작은 값이기 때문에 gradient도 작을 것이고 결국 업데이트가 잘 되지 않을 것이다.
gradient를 backprop하는 과정은
upstream gradient에 w의 gradient인 x를 곱한다.
그리고 입력 x는 어떤 내적의 결과이다.
backward pass의 과정에서 upstream gradient를 구하는 것은
현재 upstream에 가중치를 곱하는 것이다.
w를 계속해서 곱하기 때문에 backward pass에서도 forward 처럼 점점 gradient 값이 작아지게 된다.
따라서 upstream gradients는 0으로 수렴하게 된다.
여기서 upstream은 gradient가 흘러가는것이다.
loss에서부터 시작해서 최초 입력까지 흘러간다.
현재 노드를 계산하고 또 밑으로 흘러내려간다.
backprop으로 노드에 흘러 들어온 것이 upstream이다.
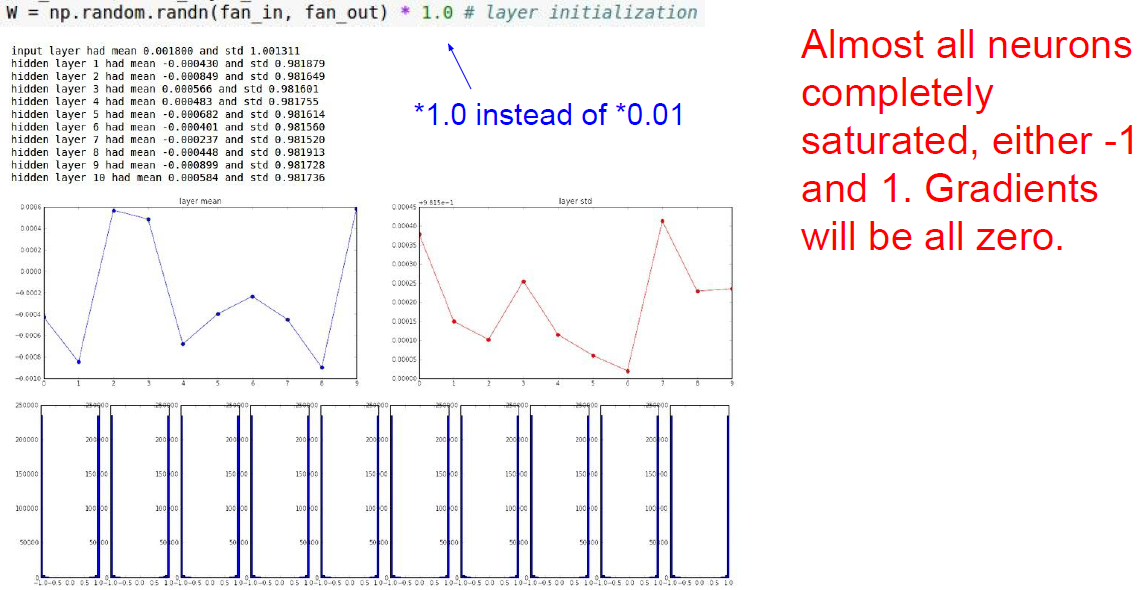
그렇다면 가중치를 좀 더 큰 값(0.01 -> 1.0)으로 초기화하면 어떨까?
이렇게 큰 가중치를 통과한 출력 wx를 구하고 이를 tanh를 거친다면 어떻게 될까?
앞서 언급했던데로 tanh에서 큰 값이 입력으로 들어오면 saturation 될 것이다.
그렇게되면 항상 -1 혹은 +1 일 것이다.
값이 saturation이 되면 gradient는 0이 되며, 가중치 업데이트가 되지 않기에 적절한 가중치를 얻기 어려워진다.
너무 작으면 사라져버리고, 너무 크면 saturation되어 버린다.

그래서 사람들이 어떻게 하면 가중치 초기화를 잘 할 수 있을까 고민했다.
널리 알려진 좋은 방법 중 하나는 Xavier initialization이다.
Glorot가 2010에 발표한 논문이다.
그림 위의 w 공식을 살펴보면
std gaussian으로 뽑은 값을 입력의 수로 scaling 해준다.
기본적으로 xavier initialization가 하는 일은 입력/출력의 분산을 맞춰주는 것이다.
입력의 수가 작으면 더 작은 값으로 나누기 때문에 좀 더 큰 값을 얻는다.
우리는 더 큰 가중치가 필요하다.
왜냐하면 작은 입력의 수가 가중치와 곱해지기 때문에
가중치가 더 커야만 출력의 분산 만큼 큰 값을 얻을 수 있다.
반대로 입력의 수가 많은 경우에는 더 작은 가중치가 필요하다.

하지만 문제가 하나 있다.
ReLU를 쓰면 잘 동작하지 않는다는 것이다.
ReLU는 출력의 절반을 0으로 만든다.
이는 결국 출력의 분산을 반토막 낸다는 것이다.
ReLU에서는 값이 너무 작아지기 때문에 잘 작동하지 않게 된다.
위의 그림은 이러한 분포가 줄어드는 현상을 나타낸다.
점점 더 많은 값들이 0이 되고 결국은 비활성(deactivated)된다.

이 문제를 해결하기 위한 논문이 있다.
여기서는 추가적으로 2를 더 나눠준다.
neuron 중 절반이 없어진다는 사실을 고려하기 위함이다.
실제 입력은 반밖에 안들어가므로 반으로 나워주는 텀을
추가적으로 더해주는 것이고 실제로 잘 동작한다.
실제로 2를 더 나눠주는 이 작은 변화는 학습에 있어서 큰 차이를 보인다.
일부 논문에서는 이러한 작은 차이가 학습이 정말 잘 되거나 아예 안되거나하는 결정하는 결과를 보이기도 한다.
gaussian의 범위로 activation을 유지시키는 것에 관련된 다른 아이디어를 살펴보자.

우리는 layer의 출력이 unit gaussian이길 원한다.
batch normalization은 unit gaussian 형태로 강제로 만들어보자는 아이디어이다.
어떤 layer로부터 나온 batch 단위 만큼의 activations가 있다고 했을 때,
우린 이 값들이 unit gaussian이기를 원한다.
현재 batch에서 계산한 mean과 variance를 이용해서 normalization 할 수 있다.
가중치를 잘 초기화 시키는 것 대신에
학습할 때 마다 각 layer에 이러한 normalization을 통해
모든 layer가 unit gaussian이 되도록 한다.
결국 학습하는 동안 모든 layer의 입력이 unit gaussian이 됐으면 좋겠다는 것이다.
그렇게하기 위해 네트워크의 forward pass에서
unit gaussian이 되도록 명시적으로 만들어준다.
각 neuron을 mean과 variance로 normalization 해주므로
이런 일을 함수로 구현하는 것이다.
batch 단위로 한 layer에 입력으로 들어오는 모든 값들을 이용해서
mean과 variance를 계산해서 normalization 해준다.
이렇게 만든 함수를 보면 미분이 가능하다.
mean과 variance를 상수로 가지고 있으면 미분이 가능해서 backprop가 가능하게 된다.

위 그림을 보면 batch당 N개의 학습 데이터가 있고 각 데이터가 D차원이라고 가정하자.
각 차원별로 mean을 각각 계산한다.
하나의 batch 내에 이걸 전부 계산해서 normalize한다.

그리고 이 BN은 FC 혹은 conv layer 다음에 넣어준다.
BN은 입력의 scale만 살짝 조정해주는 역할이기 때문에
FC와 conv 어디에든 적용할 수 있다.
conv layer에서 차이점이 있다면 normalization을 차원마다 독립적으로 수행하는 것이 아니라
같은 activation map의 같은 채널에 있는 요소들은 같이 normalize 해준다.
왜냐하면 conv 특성상 같은 방식으로 normalize 시켜야하기 때문이다.
conv layer의 경우 activation map(channel, depth) 마다 mean과 variance를 하나만 계산한다.
그리고 현재 batch에 있는 모든 데이터로 normalize 해준다.
문제는 FC를 거칠 때 마다 매번 normalization을 해주는 것이다.
위의 그림에서 tanh의 입력이 unit gaussian 형태가 맞는것인가?

normalization의 역할은 입력이 tanh의 linear한 영역에만 존재하도록 강제하는 것이다.
그렇게 되면 saturation이 전혀 일어나지 않게 된다.
하지만 saturation이 전혀 일어나지 않는것보다
얼마나 saturation이 일어날지를 조절하는것이 더 좋다.
BN은 normalization 이후 scaling 연산을 추가한다.
이를 통해 unit gaussian으로 normalize 된 값들을
감마는 scaling 효과를, 베타는 shifting의 효과를 준다.
이렇게 하면 normalized 된 값들을 다시 원상복구할 수 있다.
감마 = variance, 베타 = mean으로 하면 BN을 하기 전 값으로 돌아갈 수 있다. (오른쪽 수식)
네트워크에서 데이터를 tanh에 얼마나 saturation 시킬지를 학습하기 때문에 유연성을 얻을 수 있다.

batch normalization을 요약하면,
모든 mini-batch 각각에서의 mean과 variance를 계산한다.
그리고 mean과 variance로 normalize 한 이후에
다시 추가적으로 scaling, shifting factor를 사용한다.
BN은 gradient의 흐름을 보다 원할하게 해주며
결국 학습이 더 잘되게 해준다.
BN을 사용하면 learning rate를 좀 더 높일 수 있고
다양한 초기화 방법들을 사용해볼 수 있다.
그래서 사람들이 BN을 쓰면 학습이 더 쉬워진다고 평가한다.
또 한가지는 BN이 regularization의 역할도 한다는 것이다.
각 layer의 출력은 해당 데이터 하나 뿐만 아니라
batch 안에 존재하는 모든 데이터들에 영향을 받는다(mean, variance).
왜냐하면 각 layer의 입력은 해당 배치의 평균으로 normalize되기 때문이다.
그렇기 때문에 이 layer의 출력은 이제 오직 하나의 샘플에 대한
deterministic한 값이 아니게 되고
batch 내의 모든 데이터가 입력으로 한대 묶인다고 볼 수 있다.
그러므로 더 이상 레이어의 출력은 deterministic하지 않고
조금씩 바뀌게 되고 이는 regularization effect를 주게된다.

BN에서 mean과 variance는 학습 데이터에서 계산한다.
inference time에 추가적인 계산을 하지 않는다.
training time에서 running average 같은 방법으로
mean, variance를 계산하고 inference time에 사용한다.
이제 학습 과정을 어떻게 모니터링하고 하이퍼파라미터를 조절할 것인지 살펴보자.
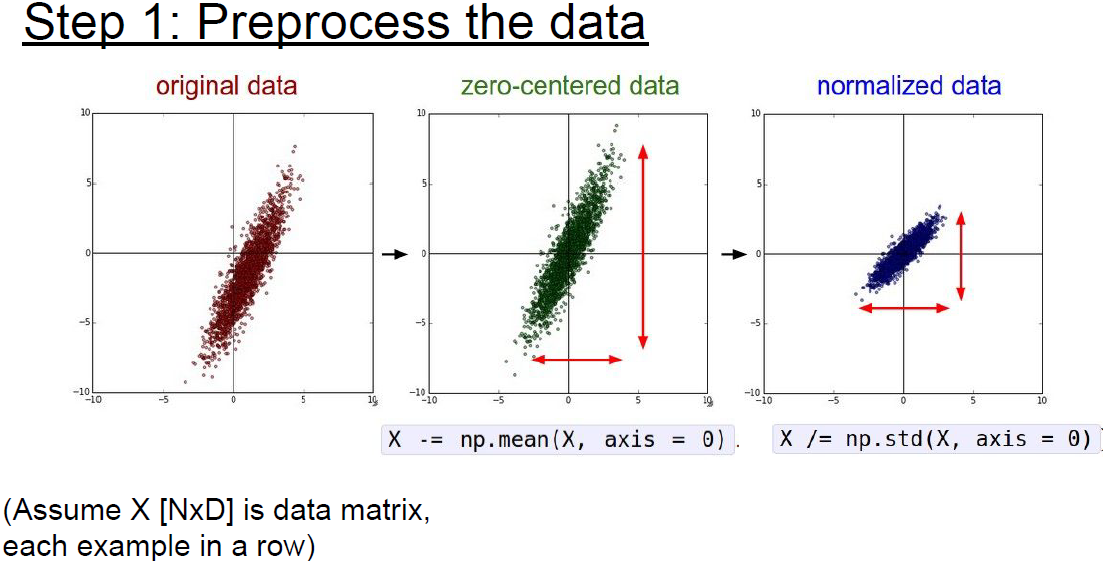
첫 단계는 데이터 전처리이다.
앞서 설명한대로 zero-mean을 사용한다.

그리고 아키텍처를 선택한다.
위의 그림은 하나의 hidden layer와 50개의 neuron을 가진 모델이다.

이후 네트워크를 초기화해야한다.
Forward pass를 하고 난 후에 계산된 loss가 그럴듯해야 한다.
만약 softmax를 사용하고자 한다면 지난 강의들을 토대로
가중치가 작은 값일 때 loss가 대강 어떻게 분포해야 하는지 이미 알고 있다.
softmax classifier의 loss는 negative log likelihood가 되어야 한다.
10개의 클래스라면 loss는 -log(1/10)이 될 것이다.
위의 그림에서 loss가 약 2.3으로 잘 동작한다는 것을 알 수 있다.
이러한 방법은 좋은 sanity check 방법이다.
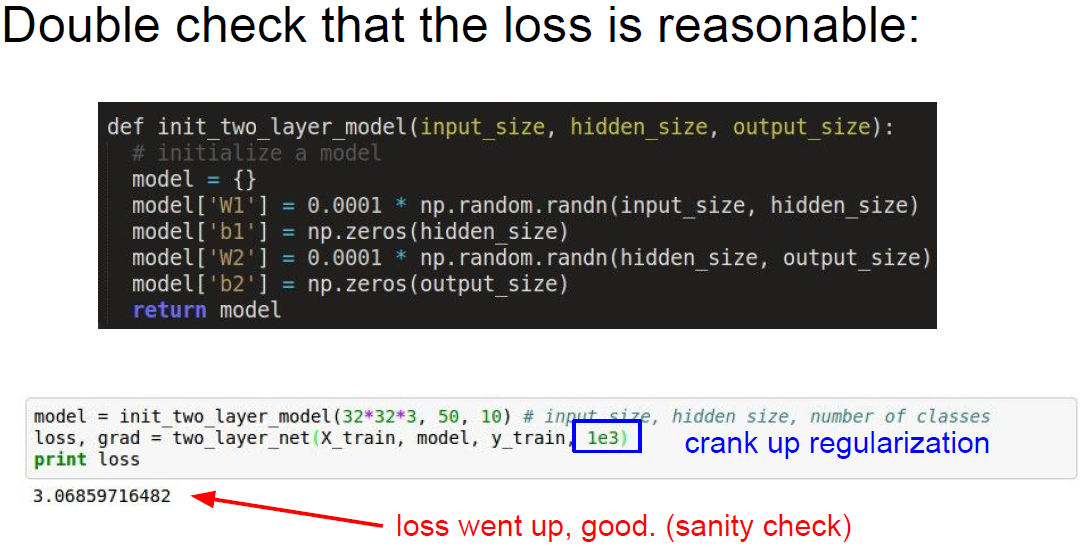
loss가 정상인것을 확인했다면 regularization term을 추가해보자.
이전은 regularization term을 0으로 했었는데
1000으로 regularization term을 추가하면 loss가 증가한다.
이것 또한 유용한 sanity check 방법이다.

처음 학습을 시작할 때 좋은 방법은 데이터의 일부만 우선 학습시켜 보는 것이다.
데이터가 적으면 당연히 over fitting이 생길 것이고 loss가 많이 줄어들 것이다.
이때는 regulaization을 사용하지 않고 loss가 내려가는지 확인한다.

위 그림처럼 epoch 마다 loss가 잘 내려가는지 확인한다.
loss가 0을 향해 꾸준히 잘 내려가는지를 확인하자.
loss가 감소함과 동시에 train accuracy는 점점 증가한다.
데이터가 작은 경우라면 모델이 완벽하게 데이터를 over fitting 할 수 있어야 한다.

이제는 전체 데이터셋을 사용하고 regularization을 약간만 주면서
적절한 learning rate를 찾아야한다.
learning rate는 가장 중요한 하이퍼파라미터 중 하나이다.
가장 먼저 정해야만 하는 하이퍼파라미터이다.
우선 몇 가지 정해서 실험을 해보자.
위의 예제에서는 1e-6으로 정했다.
그 결과로 loss가 크게 변하지 않는 것을 볼 수 있다.
loss가 잘 감소하지 않는 가장 큰 요인은 learning rate가 지나치게 작은 경우이다.
learning rate가 지나치게 작으면 gradient 업데이트가 충분히 일어나지 않고
loss가 변하지 않는다.
여기서 유심히 살펴봐야할 점은 loss가 잘 변하지 않음에도
training 및 validation accuracy가 20%가지 상승하였다.
위의 epoch 마다 확률 값들이 멀리 퍼져있기 때문에 loss가 비슷비슷한 결과를 보인다.
하지만 학습을 통해 확률이 조금씩 옮은 방향으로 바뀌기 때문에
가중치는 조금씩 바뀌지만 accuracy는 갑자기 증가할 수 있는 것이다.

learning rate를 좀 크게 바꿔보자.
1e-6에서 1e6으로 바꿔서 학습한 결과를 살펴보자.

결과를 보면 loss가 NaNs임을 볼 수 있다.
NaNs는 loss가 발산(exploded)한 것이다.
주된 이유는 learning rate가 지나치게 높기 때문이다.

이 경우에는 learning rate를 낮춰야만 한다.
그래서 3e-3으로 바꿔지만 여전히 발산한다.
보통 learning rate는 1e-3에서 1e-5 사이의 값을 사용한다.
이 범위의 값을 이용해서 cross-validation을 수행한다.
이 사이의 값들을 이용해서 learning rate가 지나치게 작은지 큰지를 결정할 수 있다.
그럼 하이퍼파라미터는 어떻게 정해줘야 할까?
하이퍼파라미터를 최적화시키고 그 중 가장 좋은 것을 선택하려면 어떻게 해야 할까?

한 가지 전략은 cross-validation이다.
cross-validation은 training set으로 학습시키고 validation set으로 평가하는 방법이다.
우선 coarse stage에서는 넓은 범위에서 값을 골라낸다.
epoch 몇 번 만으로도 현재 값이 잘 동작하는지 알 수 있다.
epoch가 많지 않아도 어떤 하이퍼파라미터가 좋은지 나쁜지를 알 수 있다.
NaN이 뜨거나 혹은 loss가 감소하지 않거나 하는 것을 확인하면서
적절히 잘 조절할 수 있을 것이다.
coarse stage가 끝나면 어느 범위에서 잘 동작하겠다는것을 대충 알 수 있다.
두 번째 fine stage에서는 좀 더 좁은 범위를 설정하고
학습을 좀 더 길게 시켜보면서 최적의 값을 찾는다.
NaNs로 발산하는 징조를 미리 감지할 수도 있다.
학습하는 동안 loss가 어떻게 변하는지를 살펴보는 것이다.
이전의 loss 보다 더 커진다면 (많이)
잘못되고 있다는 것이다.
이럴때는 다른 하이퍼파라미터를 선택해야한다.

위의 예시는 5 epoch을 돌며 coarse search를 하는 과정이다.
여기서 확인해야하는 것은 validation accuracy이다.
높은 val acc는 빨간색으로 표시되어있다.
이 빨간색 구간이 바로 fine-stage를 시작할만한 범위가 된다.
한 가지 주목할 점은 하이퍼파라미터 최적화시에는
regularization term과 learning rate를 log scale로 값을 주는 것이 좋다.
파라미터 값을 샘플링할때 10^-3 ~ 10^-6을 샘플링하지 말고
10의 차수 값만 샘플링하는 것이 좋다. (-3 ~ -6)
왜냐하면 learning rate는 gradient와 곱해지기 때문에
learning rate 선택 범위를 log scale을 사용하는 편이 좋다.
따라서 차수(orders of magnitute)를 이용하는 것이 좋다.

범위를 다시 한번 조절해보자. (오른쪽 그림)
reg는 범위를 10^-4에서 10^0 정도로 좁히면 좋을 것 같다.
val_acc 중간 범위에서 53%의 val_acc를 보이는 것을 볼 수 있다.
학습이 가장 잘 되는 구간일것이다.
그러나 문제가 있다.
아래에 있는 빨간색 박스는 가장 좋은 acc를 보인다. (0.531)
해당되는 learning rate들을 보면 전부 10e-4 사이에 존재하고 있다.
learning rate의 최적 값들이 우리가 다시 범위를 좁혀 설정한 범위의
경계부분에 집중되어 있다는 것을 알 수 있다.
이렇게 되면 최적의 learning rate를 효율적으로 탐색할 수 없을수도 있다.
실제 최적의 값이 1e-5 혹은 1e-6 근처에 존재할수도 있다.
탐색 범위를 조금만 이동시키면 더 좋은 범위를 찾을 수 있을지도 모른다.
여기서 우리는 최적의 값이 내가 정한 범위의 중앙 쯤에 위치하도록
잘 설정해주는것이 중요하다.

하이퍼파라미터를 찾는 또 다른 방법은 grid search를 이용하는 것이다.
하이퍼 파라미터를 고정된 값과 간격으로 샘플링하는 것이다.
하지만 실제로 grid search 보다는 random search를 하는 것이 더 좋다.
random search를 하는 경우는 오른쪽 그림과 같다.
random이 더 좋은 이유는
내 모델이 어떤 특정 파라미터의 변화에 더 민감하게 반응을 하고 있다고 생각해보면 (노랑 < 초록)
이 함수가 더 비효율적인 dimentionality를 보인다고 할 수 있으며 (노랑에는 별 영향을 받지 않음)
random search는 중요한 파라미터(초록)에게도 더 많은 샘플링이 가능하므로
위에 그려놓은 초록색 함수를 더 잘 찾을 수 있다.
grid layour에서는 오직 세 번의 샘플링 밖에 할 수 없으므로
good region이 어디인지 제대로 찾을 수 없다.
random search를 사용하면 important variable에서 더 다양한 값을 샘플링할 수 있다.

실제 우리는 하이퍼파라미터 최적화와 cross-validation을 많이 해야한다.
많이 해서 많은 하이퍼파라미터를 직접 돌려보고 모니터링해서 어떤 값이 좋고 나쁜지를 확인해야 한다.
loss curve를 보면서 좋은 것을 찾아서 시도해보는 일을 계속 반복해야 한다.

loss curve를 모니터링 하는데 있어서 learning rate가 정말 중요하다.
loss curve를 보고 어떤 learning rate가 좋고 나쁜지를 알아볼 수 있다.
loss가 발산하면 learning rate가 높은 것이고
너무 평평(linear)하면 낮은 것이다.
가파르게 내려가다가 어느 순간 정체기가 생기면
이 또한 여전히 너무 높다는 의미이다.
learning step이 너무 크게 점프해서 적절한 local optimum에 도달하지 못하는 경우이다.
최적의 learning rate에 대한 loss curve는 왼쪽 그림과 같다.
비교적 가파르게 내려가면서도 지속적으로 잘 내려간다면 현재 learning rate를 유지해도 좋다.

loss가 평평하다가 갑자기 가파르게 내려간다면
이는 초기화 문제일수있다.
gradient의 backprop이 초기에는 잘 동작하지 못하다가 학습이 진행되면서 회복이 되는 경우이다.

위의 그림은 accuracy를 모니터링하면 볼 수 있는 현상이다.
train acc와 val acc가 큰 차이를 보인다면 over fitting일수도 있다.
따라서 regularization 강도를 높여야 될 수 있다.
큰 차이가 없다면 아직 overfitting 하지 않은 것이고 capacity를 높일 수 있는 여유가 있는 것을 의미한다.

가중치의 크기 대비 가중치 업데이트의 비율을 확인할 필요도 있다.
먼저 파라미터의 norm을 계산해서 가중치의 규모를 계산한다.
그리고 norm을 통해 업데이트 사이즈를 계산할 수 있고
얼마나 크게 업데이트 되는지를 알 수 있다.
우리는 이 비율이 대략 0.001 정도 되길 원한다.
이 값은 변동성이 커서 정확하지 않을 수 있다.
하지만 업데이트가 지나치게 크거나 작은지에 대한 감을 어느정도 가질 수 있다.
업데이트가 너무 지나치거나 아무런 업데이트도 없으면 안된다.
'머신러닝 > CS231n (2017)' 카테고리의 다른 글
| Lecture 5: Convolutional Neural Networks (0) | 2020.09.24 |
|---|---|
| Lecture 4: Backpropagation and Neural Networks (0) | 2020.09.17 |
| Lecture 3: Loss Functions and Optimization (0) | 2020.09.14 |
| Lecture 2: Image Classification Pipeline (0) | 2020.09.12 |
| Lecture 1: Introduction (0) | 2020.09.07 |